
ABBIndustrial Networks Connecting Controllers via OPC
single PCI card/OPC server combination product that supports slave redundancy
could be found on the market. However, Woodhead offers an API to control their
PROFIBUS multi-slave card. That is, it would be possible to program an own
redundancy logic for the PCI card. The OPC server, which has to support redundancy as well, needs to be adjusted or reprogrammed. Implementing this redundancy brainpower in the personal computer, one of the two cards has to be
the active card while the other is in standby mode to appear transparently to the
AC800M bus master.
Since the SST-PBMS-PCI card neither does support line redundancy, we would
have to insert two cards in one computer and implement the line redundancy logic
as computer software. As a far less laborious alternative, the RLM01 introduced
earlier can be inserted.
The automation company Comsoft offers a hardware device called PRS to implement master redundancy in PROFIBUS DP systems [38]. It is intended to connect
two masters with the same address to one PROFIBUS. If one master fails, the device, which contains a galvanic switch, changes to the other master. The switchover
can also be initiated from outside via PROFIBUS itself or an additional Ethernet
connection. The device is intended for implementing master redundancy, which
is already done in our case. But, according to Comsoft, it is possible to “misuse”
the device for implementing slave redundancy and therefore replacing a software
solution [39]. However, logic to force a switchover would be needed anyway in order
for the system to work properly

6.2.3 OPC Communication
It is of course necessary that the OPC servers for both bus interface cards are running, as well as the bridging software, e.g. Kepware LinkMaster. In addition it
would be possible to add specific redundancy management software on the computers and interconnect them via (redundant) network and DCOM to the servers
located on the second computer. That would theoretically allow the setup of a completely redundant system, coping with the outage of two different OPC servers or
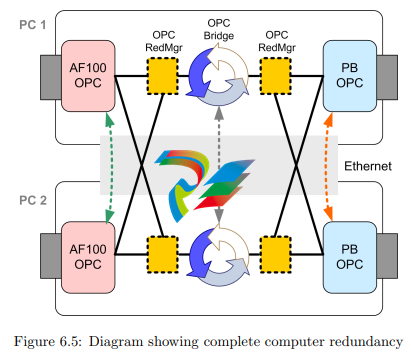
PCI cards at the same time, for example. Figure 6.5 shows the setup of such a completely redundant system. The black lines stand for OPC communication while the
three dotted arrows symbolize the redundancy communication (RedCom) between
two components.
There are different redundancy manager programs (RedMgr) available on the
market, for example Matrikon’s Redundancy Broker [40] or Kepware’s RedundancyMaster [41]. They act as a server on one side while acting as a client on the other
side, able to connect to redundant servers. The decision which server has to be considered the active one depends on the quality of the OPC connection and/or can
be configured with additional checks of values. The software therefore also allows
a restricted view on the transported data. However, these programs also insert an
additional delay in communication, and from the computers point of view they are
a weakness themselves since most likely all OPC connections are canceled if the
program fails. Therefore it would also be possible to use different products at the
same time, increasing the chance that one product keeps running when the other
fails. However, a very interesting alternative is the software OPCFailover of Jemmac Software. While its function is the same as the classical redundancy managers,
it does not insert a further relay, which also means no delay and no single point
of failure. This is reached by just managing the OPC connection, always pointing
to an active real OPC server, instead of acting as a proxy. As a drawback of this
solution it is to mention that it does not support the periodical check of OPC values
yet [42].
However, the introduction of such redundancy managers only makes sense if
the OPC servers are implemented transparently redundant, meaning that only one
sever is active at the time and without the need to send/receive some variables
twice. This is not the case at the moment. The imaginary dashed green and red
RedCom links in Figure 6.5 would have to be implemented first as discussed in the
previous sections. Otherwise the OPC bridging software in PC1 will for example
not match the variables defined in AF100 OPC Server of PC2. Dependent on
the brainpower of both OPC server logics, maybe also the OPC bridges are not
allowed to run concurrently and need an own (gray) redundancy communication.
Matrikon’s OPC Data Manager supports such a layout.
Subsuming, there is one big advantage in implementing redundancy for the OPC
connections in our system: It allows the simultaneous outage of several unequal
parts of both computers. As a further consequence of the presumed transparent
redundancy of the OPC servers, no variables have to be defined and sent twice in
the controllers, there for saving transmission time. Unfortunately, there is also an
considerable number of disadvantages:
• The support of transparent redundancy for both OPC server pairs is missing
and has to be implemented first in order to establish a clean solution for OPC
connection redundancy. This work is a huge programming task not to be
underestimated.
• When using classical redundancy managers, also an extra delay and another
-
 Hirschmann RS20-1600M2T1SDAEHH03.1.02 Rail Switch
Hirschmann RS20-1600M2T1SDAEHH03.1.02 Rail Switch -
 Hirschmann BRS30-24TX Industrial Rail Switch
Hirschmann BRS30-24TX Industrial Rail Switch -
 Hirschmann RSPM20-4T14T1EV9HHS999.9.99 Managed Ethernet Switch
Hirschmann RSPM20-4T14T1EV9HHS999.9.99 Managed Ethernet Switch -
 Hirschmann BELDEN RS40-0009CCCCSDAPHH09.0.14 / RS400009CCCCSDAPHH09014
Hirschmann BELDEN RS40-0009CCCCSDAPHH09.0.14 / RS400009CCCCSDAPHH09014 -
Hirschmann RS40 Rail Switch RS40-0009CCCCSDAE
-
 Hirschmann BELDEN RS30-0802T1T1SDAP / RS300802T1T1SDAP Fully Managed Layer 2 Compact Rail Switch
Hirschmann BELDEN RS30-0802T1T1SDAP / RS300802T1T1SDAP Fully Managed Layer 2 Compact Rail Switch -
 Hirschmann BELDEN RS20-0800M2M2SDAUHH / RS200800M2M2SDAUHH
Hirschmann BELDEN RS20-0800M2M2SDAUHH / RS200800M2M2SDAUHH -
 Hirschmann EAGLE30-04022O6TT999SCCY9HSE3F Industrial Firewall Router Switch
Hirschmann EAGLE30-04022O6TT999SCCY9HSE3F Industrial Firewall Router Switch -
 Hirschmann RS20-1600T1T1SDAEHH09.0.14 RS20 Rail Mount Ethernet Switch
Hirschmann RS20-1600T1T1SDAEHH09.0.14 RS20 Rail Mount Ethernet Switch -
 Hirschmann EAGLE0200T1T1TDDY90000HHE05.3.03 Industrial Security Router
Hirschmann EAGLE0200T1T1TDDY90000HHE05.3.03 Industrial Security Router -
Hirschmann - BELDEN MIPP-AD-1L9P
-
 HIRSCHMANN RSPM20-4Z64Z6TV9HHS9 942 106-999 RAIL SAFETY SWITCH
HIRSCHMANN RSPM20-4Z64Z6TV9HHS9 942 106-999 RAIL SAFETY SWITCH -
 HIRSCHMANN FIBEROPTIC MODULE FIP P/N: OZDFIPG3T
HIRSCHMANN FIBEROPTIC MODULE FIP P/N: OZDFIPG3T -
 HIRSCHMANN RS20-1600M2M2SDAUHH Ethernet rack-mounted switch
HIRSCHMANN RS20-1600M2M2SDAUHH Ethernet rack-mounted switch -
 HIRSCHMANN BELDEN RS20-0400T1T1SDAEHH04.0.01 / RS200400T1T1SDAEHH04001
HIRSCHMANN BELDEN RS20-0400T1T1SDAEHH04.0.01 / RS200400T1T1SDAEHH04001 -
HIRSCHMANN MM2-4FXM3 MICE Media Module
-
HIRSCHMANN RS20-0800M2M2SDAE Industrial Ethernet Rail Switch
-
 Hirschmann RS20-2400T1T1SDAP / RS20-2400T1T1SDAPHH05.0.02
Hirschmann RS20-2400T1T1SDAP / RS20-2400T1T1SDAPHH05.0.02 -
 GE MLJ1005B010H00C MLJ Digital Synchromism Check
GE MLJ1005B010H00C MLJ Digital Synchromism Check -
 ALSTOM MICROTECH DX21-M2 Digital Excitation Controller
ALSTOM MICROTECH DX21-M2 Digital Excitation Controller -
HIRSCHMANN BRS20-1200ZZZZ-STCY99HHSES
-
 HIRSCHMANN MM3-4FXM2 MICE Media Module
HIRSCHMANN MM3-4FXM2 MICE Media Module -
Hirschmann RSB20-0800T1T1SAABHH 8Port ENet Rail Switch RSB20
-
 Hirschmann MACH102-8TP Ethernet Switch
Hirschmann MACH102-8TP Ethernet Switch -
 SAACKE DDZ-M marine steam pressure atomizer
SAACKE DDZ-M marine steam pressure atomizer -
 SAACKE SKV-A marine rotary cup atomizer
SAACKE SKV-A marine rotary cup atomizer -
 SAACKE Seavis HMI05e
SAACKE Seavis HMI05e -
 Kollmorgen MMC-SD-2.0-230 Servo Drive 100-240VAC 2KW 10A Output 3PH 100-240VAC
Kollmorgen MMC-SD-2.0-230 Servo Drive 100-240VAC 2KW 10A Output 3PH 100-240VAC -
 Kollmorgen Servo drive CR10550
Kollmorgen Servo drive CR10550 -
 Kollmorgen AKD-P01207-NACN-0054 Servo Driver
Kollmorgen AKD-P01207-NACN-0054 Servo Driver -
 Kollmorgen S406M-CA-036 Servostar
Kollmorgen S406M-CA-036 Servostar -
.png) Kollmorgen AKD-B02407-NAAN-0000 Digital Servo Drive
Kollmorgen AKD-B02407-NAAN-0000 Digital Servo Drive -
 Kollmorgen SERVOSTAR S406AM-CA Digital Servo Drive
Kollmorgen SERVOSTAR S406AM-CA Digital Servo Drive -
 KOLLMORGEN SERVOSTAR 603-AS SERVO AMPLIFIER_SERVOSTAR603AS_S60301
KOLLMORGEN SERVOSTAR 603-AS SERVO AMPLIFIER_SERVOSTAR603AS_S60301 -
Kollmorgen S700 Servo Controller (S70602-NANANA-NA)
-
 Kollmorgen MPK411 controller
Kollmorgen MPK411 controller -
 KOLLMORGEN MMC-SD-1.3-460-D Smart Drive
KOLLMORGEN MMC-SD-1.3-460-D Smart Drive -
 KOLLMORGEN AKM21C-CKB2AA-00 / AKM21CCKB2AA00 Servomotor
KOLLMORGEN AKM21C-CKB2AA-00 / AKM21CCKB2AA00 Servomotor -
 BECKHOFF AX5106-0000-0200 | Digital Compact Servo Drives 1-channel
BECKHOFF AX5106-0000-0200 | Digital Compact Servo Drives 1-channel -
 BECKHOFF C3620-0000 INDUSTRIAL COMPUTER (MOTORSHELVES)
BECKHOFF C3620-0000 INDUSTRIAL COMPUTER (MOTORSHELVES) -
 Beckhoff EK1960-0000 TwinSAFE Compact Controller
Beckhoff EK1960-0000 TwinSAFE Compact Controller -
 Beckhoff C6930-0050 Control Cabinet Industrial PC
Beckhoff C6930-0050 Control Cabinet Industrial PC -
 Beckhoff CP7711-0001-0030 Industrial Computer Detection
Beckhoff CP7711-0001-0030 Industrial Computer Detection -
 Beckhoff CX1001-0111 Embedded PC CPU Module
Beckhoff CX1001-0111 Embedded PC CPU Module -
 Beckhoff C6017-0020 | Ultra-compact Industrial PC
Beckhoff C6017-0020 | Ultra-compact Industrial PC -
 Beckhoff EK1322 | 2-port EtherCAT P junction with feed-in
Beckhoff EK1322 | 2-port EtherCAT P junction with feed-in -
 Beckhoff CP2219-0010 Panel
Beckhoff CP2219-0010 Panel -
 BECKHOFF C6015-0020 ULTRA COMPACT INDUSTRIAL PC
BECKHOFF C6015-0020 ULTRA COMPACT INDUSTRIAL PC -
 BECKHOFF CX2030-0120/Standard CPU Module Embedded PC Windows PLC controller
BECKHOFF CX2030-0120/Standard CPU Module Embedded PC Windows PLC controller -
 Beckhoff CP7721-1090-0020 Panel PC
Beckhoff CP7721-1090-0020 Panel PC -
 Beckhoff PC CPU Module CX5130-0175
Beckhoff PC CPU Module CX5130-0175 -
 Beckhoff C6920-0050 Control Cabinet
Beckhoff C6920-0050 Control Cabinet -
 Beckhoff EL6631 EtherCAT 2-Port Communication Interface, Profinet RT Controller
Beckhoff EL6631 EtherCAT 2-Port Communication Interface, Profinet RT Controller -
 Beckhoff CP6202-0001-0060 touch screen panel PC
Beckhoff CP6202-0001-0060 touch screen panel PC -
 Beckhoff CP3916-1002-0000 Multi-Touch Control Panel
Beckhoff CP3916-1002-0000 Multi-Touch Control Panel -
 Beckhoff EP1809-0021 | EtherCAT Box, 16-channel digital input, 24 V DC, 3 ms, M8Preferred type
Beckhoff EP1809-0021 | EtherCAT Box, 16-channel digital input, 24 V DC, 3 ms, M8Preferred type -
 Beckhoff CX8190 PLC Embedded Industrial PC Ethernet Controller
Beckhoff CX8190 PLC Embedded Industrial PC Ethernet Controller -
 Beckhoff CX2100-0914 Power Supply for External
Beckhoff CX2100-0914 Power Supply for External -
 Beckhoff Automation CP6906-0001-0000 HMI
Beckhoff Automation CP6906-0001-0000 HMI -
 Beckhoff EP7342-0002 Module
Beckhoff EP7342-0002 Module -
 Beckhoff CX1020-0112 / CX1100-0910 / CX1020-N010 / CX1100-0003 Windows CPU
Beckhoff CX1020-0112 / CX1100-0910 / CX1020-N010 / CX1100-0003 Windows CPU -
 Beckhoff EP7211-0034 EtherCAT Box 1 Channel Motion Interface
Beckhoff EP7211-0034 EtherCAT Box 1 Channel Motion Interface -
 Beckhoff C6240-0030 Control cabinet Industrial PC
Beckhoff C6240-0030 Control cabinet Industrial PC -
 beckhoff motherboard CB1052-0004 CB1052-0004
beckhoff motherboard CB1052-0004 CB1052-0004 -
 Beckhoff AX2006-AS Servo Drive / Variable Frequency Drive
Beckhoff AX2006-AS Servo Drive / Variable Frequency Drive -
BECKHOFF CP6207-0001-0020 NSMP
-
 Beckhoff C6930-1142-0060 Industrial Computer
Beckhoff C6930-1142-0060 Industrial Computer -
 Beckhoff FC7501-0000 interface card
Beckhoff FC7501-0000 interface card -
 Beckhoff CX5140-0175 Embedded PC PLC CPU CX5140 Industrial Controller
Beckhoff CX5140-0175 Embedded PC PLC CPU CX5140 Industrial Controller -
 Beckhoff CP7802-1100-0010: High-End IP65 Control Panel with DVI/USB Extended Interface
Beckhoff CP7802-1100-0010: High-End IP65 Control Panel with DVI/USB Extended Interface -
BECKHOFF CP3716-1058-0010 CONTROL PANEL
-
 Beckhoff AX8108-0000 Single-Axis Module
Beckhoff AX8108-0000 Single-Axis Module -
 Beckhoff CU8851-0000 | USB extension, USB Extended 2.0 receiver box
Beckhoff CU8851-0000 | USB extension, USB Extended 2.0 receiver box -
Beckhoff C6017-0030 | Ultra-compact Industrial PC
-
 Beckhoff CX1001-0120/CX10010120.cx1000-n001.cx1000-n000 System Overview
Beckhoff CX1001-0120/CX10010120.cx1000-n001.cx1000-n000 System Overview -
 Beckhoff CPU Module CX5140-0155/4GB CPU Module
Beckhoff CPU Module CX5140-0155/4GB CPU Module -
 Beckhoff CP6533-0001-005: Built-in Panel PC with High-Definition Multi-Touch Control
Beckhoff CP6533-0001-005: Built-in Panel PC with High-Definition Multi-Touch Control -
 Beckhoff EL5042 | EtherCAT Terminal, 2-channel encoder interface, BiSS® C
Beckhoff EL5042 | EtherCAT Terminal, 2-channel encoder interface, BiSS® C -
 Beckhoff C6920-1080-0040: Premium Control Cabinet Industrial PC
Beckhoff C6920-1080-0040: Premium Control Cabinet Industrial PC -
 Beckhoff C6920-0060 | Control cabinet Industrial PC
Beckhoff C6920-0060 | Control cabinet Industrial PC -
 Beckhoff Embedded-PC CX5010-1121
Beckhoff Embedded-PC CX5010-1121 -
 Beckhoff CB3050-0010 Mainboard Motherboard
Beckhoff CB3050-0010 Mainboard Motherboard -
 Beckhoff PLC module CX1020-0000 Basic CPU module (service phase)
Beckhoff PLC module CX1020-0000 Basic CPU module (service phase) -
 Beckhoff CP7812-1056-0010 15" Multitouch Display Control Panel
Beckhoff CP7812-1056-0010 15" Multitouch Display Control Panel -
 Beckhoff CX5120-0115 /2GB Controller Module
Beckhoff CX5120-0115 /2GB Controller Module -
 Beckhoff CP7201-1000-0000 Industrial Panel PC
Beckhoff CP7201-1000-0000 Industrial Panel PC -
 Beckhoff Servo Motor AM8061-0JH1-0000
Beckhoff Servo Motor AM8061-0JH1-0000 -
 BECKHOFF CP6503-0001-0050 Built-in Panel PC
BECKHOFF CP6503-0001-0050 Built-in Panel PC -
Beckhoff CP3919-0010 Display G190ETN01.2 19" PCT V04. Multi-touch Control Panel
-
 Beckhoff CX5110-0112-9020/000368201 Embedded PC Intel Atom Processor
Beckhoff CX5110-0112-9020/000368201 Embedded PC Intel Atom Processor -
 Beckhoff AX8206-0000 Dual-Axis Module
Beckhoff AX8206-0000 Dual-Axis Module -
Beckhoff Nail Operating Terminal CP7032-1031-0010
-
Beckhoff AM8042-0EH1-0000 Servomotor 4.10 Nm (M0), F4 (87 mm)
-
 Beckhoff EK9300 Beckhoff CPU Module
Beckhoff EK9300 Beckhoff CPU Module -
Beckhoff CP3224-0020 Multitouch-Panel-PC
-
 Beckhoff CP2712-0000 12.1" 24VDC Touch Screen WMD0
Beckhoff CP2712-0000 12.1" 24VDC Touch Screen WMD0 -
 BECKHOFF CX5240-0195 / 0000289234 Embedded PC 40 GB CFast Card
BECKHOFF CX5240-0195 / 0000289234 Embedded PC 40 GB CFast Card -
 Beckhoff CP6932-1000-0000 Control Panel
Beckhoff CP6932-1000-0000 Control Panel -
 BECKHOFF CX5120-0121 PLC Module
BECKHOFF CX5120-0121 PLC Module -
 Beckhoff EL3218 | EtherCAT Terminal, 8-channel analog input
Beckhoff EL3218 | EtherCAT Terminal, 8-channel analog input -
Beckhoff C6640-0050 | Control cabinet Industrial PC
-
 Beckhoff Cx5130-0120/4GB Embedded-PC
Beckhoff Cx5130-0120/4GB Embedded-PC -
 BECKHOFF CX2030-0122 PLC PROCESSOR
BECKHOFF CX2030-0122 PLC PROCESSOR -
 BECKHOFF CX5020-0122 Controller Module
BECKHOFF CX5020-0122 Controller Module -
 Beckhoff CP3915-0000 Multitouch Panel
Beckhoff CP3915-0000 Multitouch Panel -
 BECKHOFF EL3014 | EtherCAT Terminal
BECKHOFF EL3014 | EtherCAT Terminal -
 BECKHOFF Industrial Computer c6920-1057-0030
BECKHOFF Industrial Computer c6920-1057-0030 -
 Beckhoff CX5130-0141/4GB CX5130-0141 Embedded PC
Beckhoff CX5130-0141/4GB CX5130-0141 Embedded PC -
 Beckhoff C6240-1052-0040 4-086-06-3073 Industrial Computer
Beckhoff C6240-1052-0040 4-086-06-3073 Industrial Computer -
 Beckhoff CX5140-0135 /4GB High-Performance Embedded Industrial PC
Beckhoff CX5140-0135 /4GB High-Performance Embedded Industrial PC -
 Beckhoff C6515-1001-0000 Industrial PC
Beckhoff C6515-1001-0000 Industrial PC -
 Beckhoff AX5103-0000-0200 - Digital Compact Servo Drives
Beckhoff AX5103-0000-0200 - Digital Compact Servo Drives -
 Beckhoff CX2030-0130-1003/4GB Basic CPU module
Beckhoff CX2030-0130-1003/4GB Basic CPU module -
 Beckhoff AX8620-0000 Power Supply Module
Beckhoff AX8620-0000 Power Supply Module -
 Beckhoff CX9020-0111 module with
Beckhoff CX9020-0111 module with -
 Beckhoff EL7332 PLC Module
Beckhoff EL7332 PLC Module -
 BECKHOFF CP7709-0001-0020 HMI
BECKHOFF CP7709-0001-0020 HMI -
 Beckhoff CX5120-0155/2GB Embedded PC
Beckhoff CX5120-0155/2GB Embedded PC -
 BECKHOFF CP7037-1037-0010 OPERATOR INTERFACE TOUCHSCREEN
BECKHOFF CP7037-1037-0010 OPERATOR INTERFACE TOUCHSCREEN -
 Beckhoff EK9000 | ModbusTCP/UDP Bus Coupler
Beckhoff EK9000 | ModbusTCP/UDP Bus Coupler -
 Beckhoff Touch Panel Screen CP6020 -0000-0000
Beckhoff Touch Panel Screen CP6020 -0000-0000 -
 Beckhoff CX2020-0121 Module FAST Shipping
Beckhoff CX2020-0121 Module FAST Shipping -
 Beckhoff CX2030-0125 Basic CPU Module
Beckhoff CX2030-0125 Basic CPU Module -
 Beckhoff CP3918-0000 Multi-Touch 18.5" Control Panel
Beckhoff CP3918-0000 Multi-Touch 18.5" Control Panel -
 Automotion LC4A00010 DC BL Motor Control, ATS, Sub Assy, SCP, 115VAC,
Automotion LC4A00010 DC BL Motor Control, ATS, Sub Assy, SCP, 115VAC, -
 500T-115VAC - VAS ENGINEERING - DORIC 500 SERIES DIGITAL TEMP INDICATOR
500T-115VAC - VAS ENGINEERING - DORIC 500 SERIES DIGITAL TEMP INDICATOR -
 Honeywell X-DCS2000/EN Digital Integrated System Manager 50/60Hz 100-240V #4
Honeywell X-DCS2000/EN Digital Integrated System Manager 50/60Hz 100-240V #4 -
 Kollmorgen S60600 Servostar600 606-Fan 4 kVA, 6 A, 3 X 230 - 480 V
Kollmorgen S60600 Servostar600 606-Fan 4 kVA, 6 A, 3 X 230 - 480 V


